6 Open Source Tools to Query OpenStreetMap
July 29, 2024
14 min read
OpenStreetMap (OSM) is one of my favorite datasets because it has anything and everything. If it could conceivably exist on a map, it probably exists in OpenStreetMap. Whether it's military bases, lakes, hedges, or power lines, it can all be mapped in OSM.
But the scope of this data can be daunting. The entire planet file takes up a whopping 1,931 GB uncompressed.1 As such, using this data can require a lot of RAM and a lot of time.
Luckily, there are many open source tools freely available to help make sense of this large dataset. In my experience creating projects with OSM, I've used many of these tools to create interesting visualizations and to answer questions about the world we live in.
1. Overpass Turbo
Overpass Turbo is a "web based filtering tool for OpenStreetMap". The tool provides a frontend for the Overpass API, which uses a procedural query language to analyze OSM data.
As an example, here is a query to find all the hotels in the given area.
[out:json][timeout:25];
// gather results
nwr["tourism"="hotel"]({{bbox}});
// print results
out geom;
The first line is saying we want the output formatted as JSON, and we'll wait up to 25 seconds for a result before timing out.
The second line is to search for all nodes, ways, and relations (nwr) that have the tag tourism=hotel inside the current bounds of the map.
The last line just prints the results.
To me, the procedural syntax can be a bit hard to read compared to a declarative language like SQL, so I usually rely on assistance for more complex queries.
The Overpass Turbo has a wizard that allows you to construct simple queries from natural text. ChatGPT is also decent at writing them.
"Write an overpass query to find all Italian restaurants in Virginia"
[out:json];
area["ISO3166-2"="US-VA"]->.searchArea;
(
node["amenity"="restaurant"]["cuisine"="italian"](area.searchArea);
way["amenity"="restaurant"]["cuisine"="italian"](area.searchArea);
relation["amenity"="restaurant"]["cuisine"="italian"](area.searchArea);
);
out center;
This query2 produces the following map of 291 results after about 10 seconds.
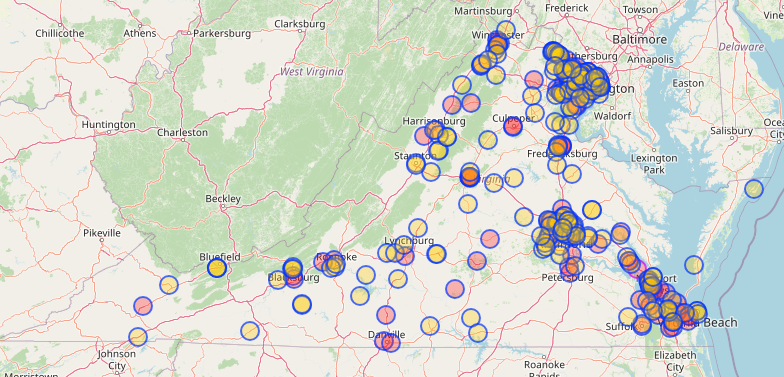
Resource Limits
In order to fairly allocate resources for different queries, Overpass has limitations on the size and duration of each request.
- The default timeout for a query is 180 seconds
- The default maximum RAM usage for a query is 512 MiB
- These limits can be adjusted by adding fields like
[timeout:600]or[maxsize:1073741824]to a query. (This was required for finding all Italian restaurants in the US without the query timing out) - However, the maximum memory that can be requested depends on the current server load 3
For example, if we wanted to find all the Italian restaurants in the US, we'd need to add
[timeout:600] or some other large number in order to get a response.
[out:json][timeout:600];
area["ISO3166-1"="US"]->.searchArea;
nwr["amenity"="restaurant"]["cuisine"="italian"](area.searchArea);
out center;
This query ended up taking 328 seconds (5.46 minutes) to execute and returned 7,116 results.
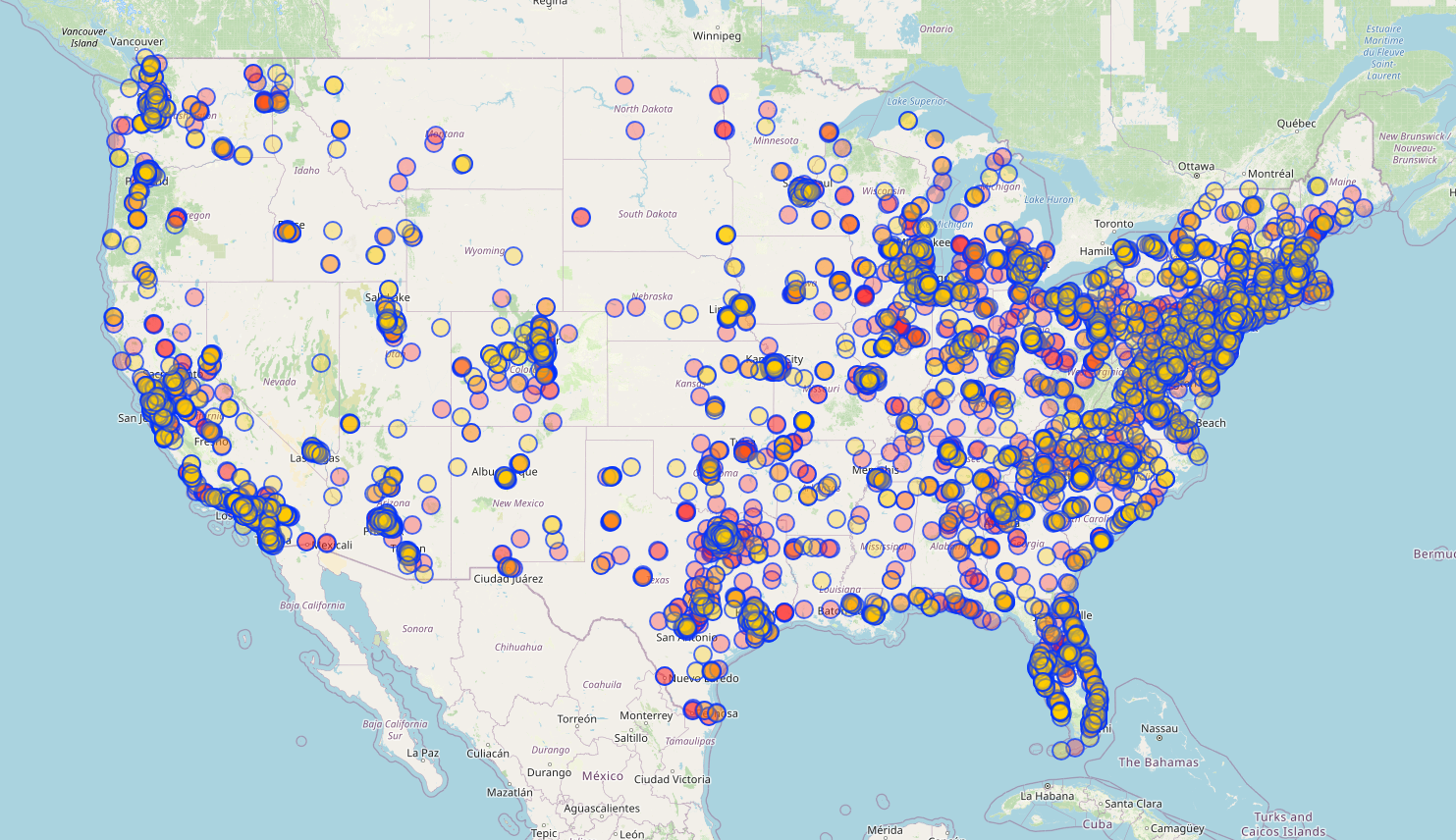
Pros
- Doesn't require any local tools and can be accessed from the browser
- Allows for easy exporting in various formats
- Wizard or ChatGPT allows constructing queries in natural language
Cons
- Query language is hard to write and harder to read (in my opinion)
- Performance for large queries can be slow
- Shared server resources make it unpredictable whether a query will be rejected or not
2. osm2pgsql + PostGIS
osm2pgsql is a command line tool that's used to load openstreetmap data into a PostGIS4 database. Since PostGIS provides an index for geospatial data, this tool is useful for loading data that needs to be queried multiple times.
PostGIS is a powerful geospatial extension for PostgreSQL, which lets you make complicated geospatial queries like "which hotels exist in this state" or "sort these bus stops by distance to my house".
Setup
I always forget how to set this up from scratch, so I made a github repo that manages most of it for me.
You can clone the repo or just copy the 3 files into a local directory.
Just run
docker compose up
To start up a PostGIS instance.
To get started with this tool, you can download an extract of OpenStreetMap from Geofabrik.
Downloading the data
OpenStreetMap is available in many different data formats, but the most compressed version is the osm.pbf format, which uses Google's protobuf library5.
I use one of two options to download the data:
You Wouldn't Download A Planet
OpenStreetMap provides an official link to download the entire "planet" file. This file contains everything mapped across the entire globe. As you might expect, this means it's pretty big - 76 GB at a minimum.
I recommend the official torrent file because it's faster than downloading it straight from the server.
Using this file is necessary for a global project, but if you can reduce the scope of your project, it's faster to use a subset of this data. For example, only the data in your country.
This brings us to...
Geofabrik extracts
Geofabrik is a German company that generously provides downloads for geographic extracts of the planet file. This means you can get a file that only has the data for your continent, country, or even just your state.
These extracts can be found here. You can click on the "Sub Region" name to get more specific extracts. E.g. clicking on "North America" from this page takes you to a list of country extracts. Clicking on "United States of America" takes you to a list of states.
Importing the data
Install the osm2pgsql tool locally with apt-get install osm2pgsql on linux.
Instructions for other operating systems can be found
here.
Once it is installed, you can run this command to import the data into the PostGIS instance we just spun up.
Replace the very last argument with the path to your osm.pbf file.
PGPASSWORD=password osm2pgsql --create --verbose \
-U postgres -H localhost -S osm2pgsql.style \
~/Downloads/virginia-latest.osm.pbf
Importing the data will take longer for larger files, which is why using an extract file is recommended.
For the Virginia extract, this took about 1 minute. For North America, it takes many hours, and for the entire planet, it would take at least a day6.
Querying the data
You can connect to the PostgreSQL instance with:
psql postgresql://postgres:password@localhost:5432
The important tables in this DB are:
postgres=# \dt
List of relations
Schema | Name | Type | Owner
----------+--------------------------+-------+----------
public | planet_osm_line | table | postgres
public | planet_osm_point | table | postgres
public | planet_osm_polygon | table | postgres
Note that these are named planet_ regardless of the extract you use.
These 3 tables represent the data in different forms.
planet_osm_point includes point features that have a single coordinate.
E.g. a restaurant might be tagged as a single location.
planet_osm_line represents linear features, such as a road.
planet_osm_polygon contains polygon features, such as a rectangular building.
For example, if we wanted to find the 10 closest restaurants to a location, we could use this query.
SELECT name,
way <-> ST_Transform(ST_GeomFromText('POINT(-80.885767 36.687606)',4326),3857) AS dist
FROM
planet_osm_point
WHERE amenity='restaurant'
ORDER BY
dist
LIMIT 10;
name | dist
--------------------------------+--------------------
Bamboo Garden | 313.9426901179711
Kyoto | 457.7719195565756
El Rio Grande | 522.2405953055143
Applebee's | 615.9410139558521
Curo's Pizza | 696.0226083422809
RJ's Pizza and Subs | 1054.0382206609697
Tlaquepaque Mexican Restaurant | 1116.4914574194884
Porky's Steack and Buffet | 1630.1301571093247
County Line Cafe | 1660.6244485206985
Pizza Hut | 1792.4252730858987
(10 rows)
Thanks to the geospatial indexing PostGIS provides, this query returns in under 0.567 ms.
Restaurants might plausibly be represented as a polygon as well,
because sometimes mappers use the building outline for that tag,
so we could modify the query to use planet_osm_polygon and the
centroid of the way.
postgres=# SELECT name,
ST_Centroid(way) <-> ST_Transform(
ST_GeomFromText('POINT(-80.885767 36.687606)',4326),
3857
) AS dist
FROM
planet_osm_polygon
WHERE amenity='restaurant' ORDER BY
dist
LIMIT 10;
name | dist
------------------------+--------------------
Valley Diner | 31747.918873591883
Shoney's | 40739.071336328416
Waffle House | 40871.59098932903
Bob Evans | 40977.497308169375
Cracker Barrel | 41119.80651892602
Applebee's | 41590.716594290105
Ruby Tuesday | 44297.93733469305
Dining Hall | 45714.815139316204
Joey's Country Kitchen | 51971.85464808888
Pizza Plus | 52375.136364474296
(10 rows)
It's less likely that restaurants are represented like this, but it doesn't hurt to consider this edge case when dealing with OSM data.
styling on osm2pgsql
You might have wondered what the osm2pgsql.style file inside my repo does.
This is called the "style" file, and it's used to control which
OSM tags get imported into PostGIS.
Unfortunately, if you want to query for a tag that's not already in this file, you'll need to go back and re-import the data.
For this reason, I recommend developing your code with a small extract first and then going back to import your larger dataset.
Let's say we want to find all the Italian restaurants in Virginia again.
Well, we can't yet, because the default osm2pgsql.style file doesn't contain
the cuisine tag, so it didn't get imported.
We can add this with:
echo "node,way cuisine text polygon" >> osm2pgsql.style
Then re-run the import
PGPASSWORD=password osm2pgsql --create --verbose -U postgres -H localhost -S osm2pgsql.style ~/Downloads/virginia-latest.osm.pbf
Now we can run:
SELECT name, osm_id
FROM planet_osm_point
WHERE amenity='restaurant' AND cuisine='italian';
Which takes 44 ms for 195 rows.
And the same query for polygons:
SELECT name, osm_id
FROM planet_osm_polygon
WHERE amenity='restaurant' AND cuisine='italian';
Which takes 274 ms for 97 rows.
Pros
- Very fast geospatial queries after initial data import
- Allows you to use SQL
- Uses PostgreSQL / PostGIS, which are very well supported tools
Cons
- Requires an initial import which can take anywhere from minutes to days
- Requires knowing the tags you will want to query in advance of the import
3. DuckDB
DuckDB is a column-oriented relational database that was first released in 2019. Installation instructions can be found here.
One of the coolest parts of this DB is the experimental ST_ReadOsm() function.
Unlike osm2pgsql, which requires loading the entire compressed file into
a separate database, ST_ReadOsm() allows you to query the compressed file directly.
Run the duckdb executable from wherever you installed it.
~/Downloads/duckdb
v1.0.0 1f98600c2c
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
Then add the spatial extension into DuckDB:
INSTALL spatial;
LOAD spatial;
Finally, you can query your osm.pbf file directly:
D SELECT COUNT(*) FROM st_readOSM('/home/wcedmisten/Downloads/virginia-latest.osm.pbf') WHERE tags['amenity'] = ['restaurant'] AND tags['cuisine'] = ['italian'];
┌──────────────┐
│ count_star() │
│ int64 │
├──────────────┤
│ 292 │
└──────────────┘
This query took 663 ms on my machine.
The really impressive part was how this performs on larger datasets. On the 15 GB north-america-latest.osm.pbf file, I could query for all Italian restaurants in just 24 seconds.
SELECT COUNT(*) FROM st_readOSM('/home/wcedmisten/Downloads/north-america-latest.osm.pbf') WHERE tags['amenity'] = ['restaurant'] AND tags['cuisine'] = ['italian'];
100% ▕████████████████████████████████████████████████████████████▏
┌──────────────┐
│ count_star() │
│ int64 │
├──────────────┤
│ 8068 │
└──────────────┘
This wouldn't be great on its own, but it does avoid having to load the 15 GB dataset into PostgreSQL, which would take multiple hours on my computer.
Caveats
One issue with this function is that it saves time by not constructing geometries during the query. This means that some of the queries you can do relating to geometries are limited or require convoluted workarounds.
It should also be noted that this extension is still experimental.
I recently filed an open issue7 because many results were missing when querying all restaurants from the planet file. However, the performance of this extension is quite promising, because it affords a lot of flexibility compared to the osm2pgsql approach. There's no need to re-import data if you realize you want to query an extra tag.
Pros
- High performance, can query large OSM extracts pretty fast without upfront indexing
Cons
- Doesn't construct geometries automatically, which limits some queries
- Still experimental
4. QLever
I discovered this tool while researching this post.
QLever is a tool that allows querying an RDF representation of OpenStreetMap using a query language called SPARQL. This basically means OSM was converted into a knowledge graph, and we can query it to find data that matches the specifications of our query.
For example, this query is used to find all the Italian restaurants in Virginia.
PREFIX geo: <http://www.opengis.net/ont/geosparql#>
PREFIX osmkey: <https://www.openstreetmap.org/wiki/Key:>
PREFIX ogc: <http://www.opengis.net/rdf#>
PREFIX osmrel: <https://www.openstreetmap.org/relation/>
SELECT ?osm_id ?hasgeometry WHERE {
osmrel:224042 ogc:sfContains ?osm_id .
?osm_id geo:hasGeometry/geo:asWKT ?hasgeometry .
?osm_id osmkey:amenity "restaurant" . ?osm_id osmkey:cuisine "italian" .
}
The real meat of the query is below the line ending in WHERE {
osmrel:224042 ogc:sfContains ?osm_id .
Searches for features within relation 224042, which is the state of Virginia8
?osm_id geo:hasGeometry/geo:asWKT ?hasgeometry .
Returns the geometry of the result, bound to the variable ?hasgeometry
?osm_id osmkey:amenity "restaurant" . ?osm_id osmkey:cuisine "italian" .
Searches for features with the tags amenity=restaurant and cuisine=italian
This query takes 3 ms of server computation time (plus a bit more to send it to our client).
This tool can join queries against wikipedia and wikidata, allowing for some unique use cases.
Pros
- Browser based interface, don't need to worry about local installation
- Allows easily joining on other data sources like Wikipedia
Cons
- SPARQL query language is common for RDF data, but still fairly niche overall
- OSM data lags by about 2 weeks
5. Nominatim
Nominatim is the official geocoder for openstreetmap.org. Geocoders are a more specific type of querying tool that look up a location (coordinates) based on an address or other textual information. E.g. "101 Main St. Richmond VA" -> (37.5432629,-77.4461068)
Often times you might need one if your dataset doesn't have coordinates, and only addresses.
Another use would be for allowing a user to look up their own location for context on a map.
Nominatim provides a public API to do this, but it has rather strict limitations on how it can be used. For example, it cannot be requested more than once/second.
Since it's open source, it can also be self-hosted, but it has fairly hefty hardware requirements. They recommend 128 GB of RAM for the whole planet.9
Nominatim is also more limited when a full address is not provided, or the address contains typos.
Lastly, if the address is not in OSM to begin with, its location cannot be found by Nominatim.
Pros
- Established geocoder software
- Provides a way to map an address to a location
Cons
- Limited usage for public API
- Requires powerful hardware to self-host
6. Pelias
Pelias is a newer geocoder service that was created in 2014 and open sourced in 2017.
The service uses elasticsearch on the backend to provide a more robust geocoder service. It also pulls from supplementary sources for address data, like OpenAddresses.10 This improves the odds of finding a match from your query, since OSM doesn't have every address.
For self-hosting the planet, only 16 GB of RAM are needed according to the official docs.11
The pelias docker repo contains a convenience script for setting up the service using data from Portland, Oregon. It took around 10 minutes to download and prepare the data. Once this is running you can query it locally with:
curl http://localhost:4000/v1/search?text=1911+Main+St
Pros
- More robust geocoding capabilities compared to Nominatim
- Docker image makes setup quick and convenient
Cons
- No public API at all, but there is a free trial
- Self-hosting requires managing an Elasticsearch instance yourself, which may be complex
Getting Started
Working with OSM can seem daunting at first, but I hope this explanation will help you take the first steps to answering new questions and building cool stuff!
In addition to many wonderful tools, the OpenStreetMap community is incredibly helpful to newcomers. I recommend reaching out to the OSM Discord, Slack, or the official forum if you need help.
Acknowledgements
Special thanks to everyone in the OSM community who helped me research this article! Especially to Minh Nguyễn who has helped me numerous times over the years.