Evaluating Mechanical Keyboard Delivery Estimates with Python Web Scraping
July 13, 2022
15 min read
Background
A few years ago, I entered the hobbyist world of mechanical keyboards. To some, keyboards are just a means of putting symbols into a computer. But there are droves in the hobbyist community obsessed with the little details of keyboards: their sound, the activation force of each keypress, and most especially the visual A E S T H E T I C of the keyboards. The most devoted hobbyists even machine, assemble, solder, and program their keyboards from scratch.
Even though I'm an amateur, it's a fun hobby to get into.
The hobby is frequently discussed on Reddit at /r/MechanicalKeyboards. The community features users showing off their keyboards, discussing new releases, and interacting with designers and manufacturers.

/u/nurupism's keyboard collection caseCustom keycaps are of particular interest to the community. These small plastic covers provide a means for endless creativity and customization. They are mostly a standard size and can be swapped out easily to give your keyboard a new look. As such, they are a popular product in the community.
Group Buys
Because the hobby is relatively niche, custom keycap designers and manufacturers use a unique model for selling new products: a Group Buy.
A Group Buy involves collecting orders (and payments) for a limited time period before any product has even been manufactured. Once the buy-in period is over, the designer and manufacturer work together to create the product. This business model is similar to a Kickstarter campaign.
Sometimes these products are even bought by speculators, hoping to resell them for a much higher price than the cost of the Group Buy. Aftermarket prices can be hundreds of dollars more than the original cost of the product, due to limited availability.
Buy-in
In February of 2021, I saw a group buy posted on Reddit for a new run of keycaps that I had my eyes on for a while: GMK Dots. These were sold by a well-reputed company according to /r/MechanicalKeyboards, called novelkeys.com
The keycaps are styled as dots of varying colors, replacing all the symbols on the keyboard. My current set of keycaps have no markings at all, so this appealed to me, and many others on /r/MechanicalKeyboards.

Perhaps bored from a year of pandemic isolation, I went all in and ordered a set. It took a leap of faith to buy a product that wouldn't even exist for another year.
Delays
The initial estimated delivery when I ordered these keycaps was Q1 2022. That estimate, along with many other product estimates, has since slipped. These estimates are provided by the "Group Buy Leader", which is the person organizing/coordinating the Group Buy, and not Novelkeys.com. As of July 2022, the estimated delivery is for Q3 of this year.
These delivery estimates and other status information are posted on a webpage that looks like this:
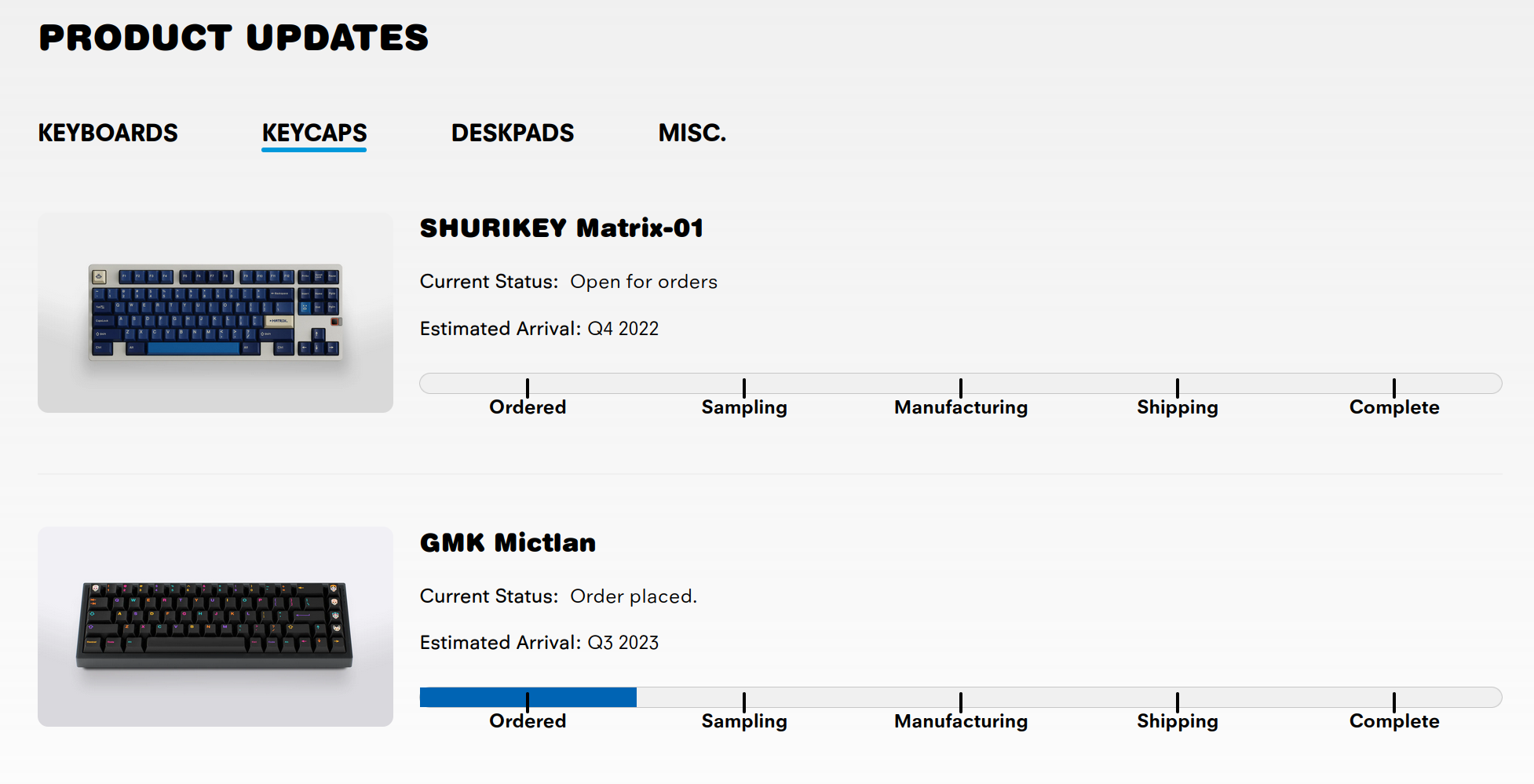
Analyzing the Data
This got me curious to know how far other delivery estimates have slipped. So I decided to scrape the product updates page and all historical snapshots of the page that have been saved on archive.org.
Luckily for me, these snapshots were available back to November 2019.
Downloading the Data
Using a tool called waybackpack, I was able to download all historical
snapshots from archive.org with one command:
waybackpack https://novelkeys.com/pages/product-updates \
-d ~/Downloads/novelkeys-wayback
This downloaded a bunch of HTML pages in a path like:
~/Downloads/novelkeys-wayback/20220307063439/novelkeys.com/pages/product-updates
Where the directory 20220307063439 is a timestamp of the snapshot, similar
to ISO-8601 format, providing the date and time of capture.
Missing Data?
Unfortunately, these snapshots only went back to Sept. 3, 2021.
Upon further inspection, this was the date when the website went through a
redesign, and moved domains from novelkeys.xyz to novelkeys.com.
So I also scraped the older website data with:
waybackpack https://novelkeys.xyz/pages/updates \
-d ~/Downloads/novelkeys-wayback
In total, the data includes 39 snapshots of the product updates page, ranging from November 2019 to June 2022. A span of about two and a half years. This averages out to around 1.25 snapshots per month, although the snapshots are not a uniform distribution.
Scraping Novelkeys.com
The newer website design ended up being much easier to scrape. It used meaningful class IDs for web elements:
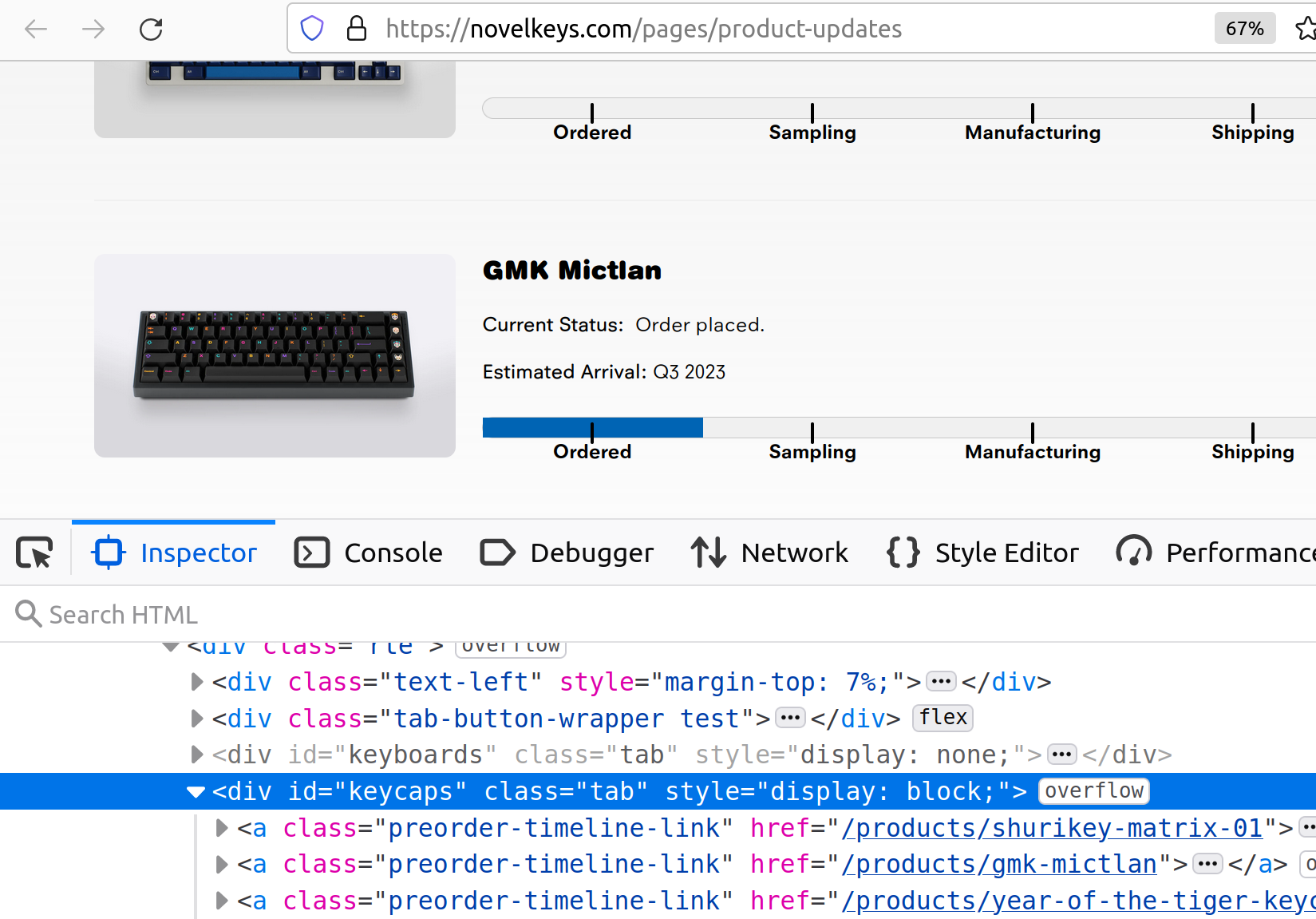
This allowed me to easily scrape the page for product updates and find:
- Product Name
- Category (keyboard, keycap, deskpad, etc.)
- Status
- Delivery Estimate
Using the following python function:
def _get_product_info(soup, category):
data = {}
# find all the product divs under the category tab
all_products = soup.select_one("#" + category).find_all(
"div", {"class": "preorder-timeline-details"}
)
for product in all_products:
# the product name header uses
# `preorder-timeline-title` class
name = product.find(
"h2", {"class": "preorder-timeline-title"}
).text
product_details = product.find_all("p", {})
# status is always the first paragraph element
status = product_details[0].text.strip()
# sometimes there is an estimate, but not always
estimate = None
if len(product_details) > 1:
estimate = product_details[1].text.strip()
data[name] = {"status": status, "category": category}
if estimate:
data[name]["estimate_text"] = estimate
# split the presentation text to get just estimate
# e.g: `Q1 2022`
data[name]["estimate"] = estimate.split(
"Estimated Arrival:"
)[1].strip()
return data
This function was invoked for each file by:
# Load the html file into BeautifulSoup
soup = BeautifulSoup(fp, "html.parser")
# List of all 4 categories from tab IDs
categories = ["keycaps", "keyboards", "deskpads", "switches"]
category_data = [_get_product_info(soup, category)
for category in categories]
Scraping novelkeys.xyz
Unlike the new design, the old website design made scraping much harder because it used randomly generated class names, rather than meaningful ones. This was probably a result of using a styling system like CSS modules, which relies on uniquely generated class names.
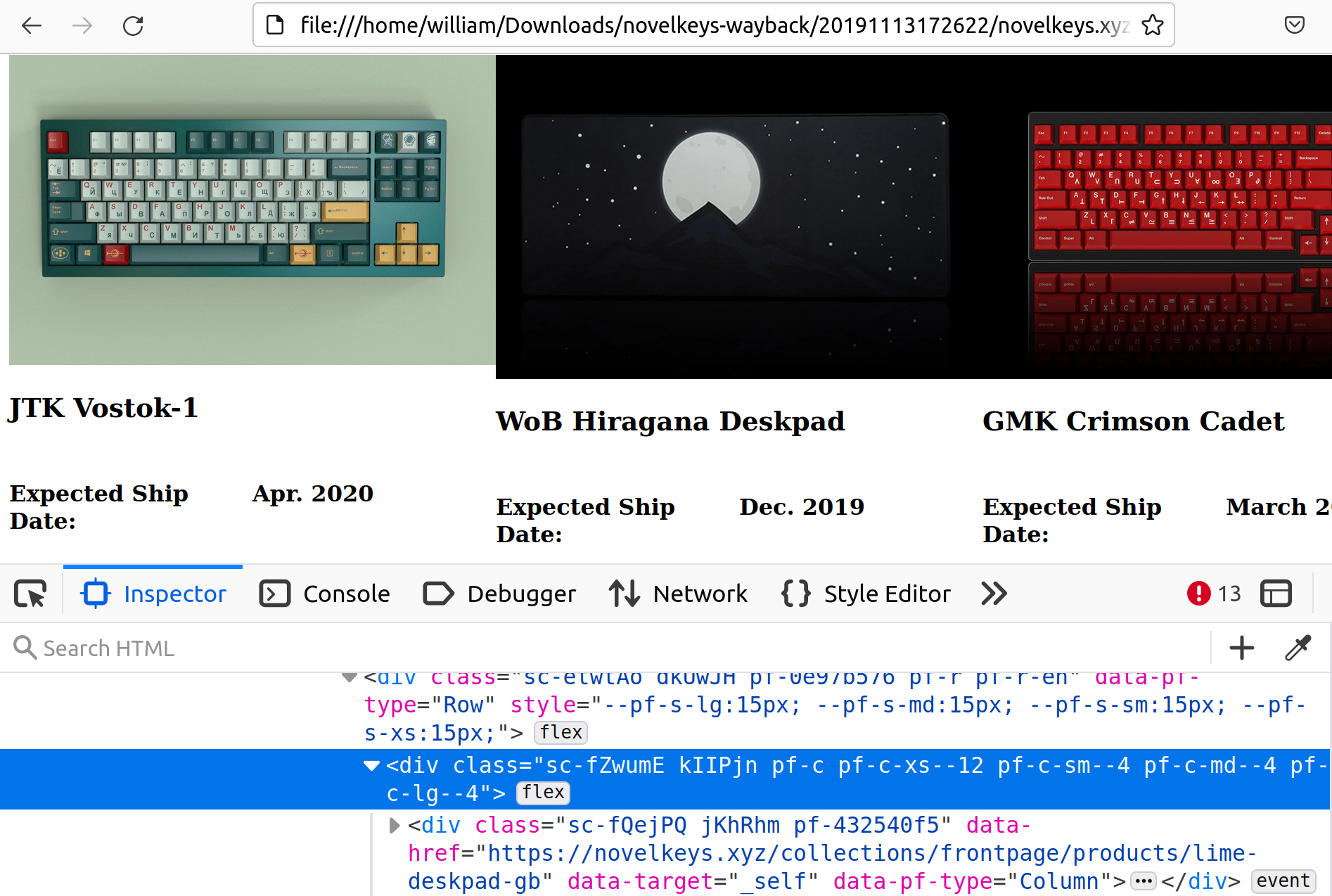
My workaround for this was noticing a pattern: each product div element has an attribute
like data-href="https://novelkeys.xyz/collections/frontpage/products/lime-deskpad-gb"
which provides the URL of each product.
This meant I could find all product <div>'s with a query
matching this attribute with a regex:
all_products = soup.find_all(
"div",
attrs={"data-href":
re.compile(r"https://novelkeys.xyz/products/*")
}
)
Unfortunately, for each product <div>, there was no meaningful tagging
for different text elements. But, the ordering was consistent, so I used
that alone to infer each section's meaning.
I also used the number of text elements in each section to infer the status of the
product. For example:
Live Group Buy

Has 3 elements:
- Name
- The text "Expected Ship Date"
- Estimated ship date
In Progress

Has 5 elements:
- Name
- The text "Expected Ship Date"
- Estimated ship date
- The text "Status:"
- Status of the product
Completed

Has 2 elements:
- Name
- The text "Group Buy Completed"
The following code scrapes the old design, classifying each product's status based on the previous assumptions about ordering. It also uses an assert statement to verify the pages all conform to that assumption.
for i in all_products:
item_info = i.find_all("span", attrs={"data-pf-type": "Text"})
name = item_info[0].text.strip()
# grouping status by number of matches:
# 5: in progress
# 3: live
# 2: completed
assert len(item_info) == 5 or
len(item_info) == 2 or
len(item_info) == 3
# in progress
if len(item_info) == 5:
data[name] = {}
if len(item_info) > 2:
data[name]["estimate"] = item_info[2].text.strip()
if len(item_info) > 4:
data[name]["status"] = item_info[4].text.strip()
# live
elif len(item_info) == 3:
data[name] = {}
data[name]["estimate"] = item_info[2].text.strip()
# don't include completed products in the data
Aggregating the Data
By combining both these scripts, I was able to aggregate the product update data into one large JSON dictionary, with the following shape:
"20220617092727": {
"BOX 75 Keyboard": {"category": "keyboards",
"estimate": "Q3 2022",
"estimate_text": "Estimated Arrival: Q3 2022",
"status": "In production."},
"Cherry RAW": { "category": "keycaps",
"estimate": "Q3 2022",
"estimate_text": "Estimated Arrival: Q3 2022",
"status": "Order placed."},
In this object structure, each top-level key is a timestamp of the website snapshot. Each value is an object mapping product names to properties of the product like category, estimate, and status.
Cleaning the Data
Now that we have the data aggregated, let's take a look at what products are in the data:
all_products = set()
for timestamp, val in data.items():
for name in val.keys():
all_products.add(name)
print(len(all_products))
pprint.pprint(all_products)
157
{'Aluvia Keycaps',
'Analog Dreams Deskpads',
'Analog Dreams R2 Deskpad',
'Arctic Deskpad',
'Awaken Deskpad',
'Awaken Deskpads',
...
'WoB Hiragana Deskpad',
'Wraith Deskpad',
'X-Wing',
'Yuri Deskpad',
'wilba.tech Salvation Keyboard'}
Right away, there are some problems with the data. Some of the products have typos or inconsistent names at some point in the historical data. We'll want to clean that up before going further into analysis.
By grouping the timestamp and status of these products, we can see that these naming inconsistencies are sometimes caused when the product is moved to "Complete":
all_products = {}
for timestamp, val in data.items():
for name in val.keys():
if name not in all_products:
all_products[name] = []
all_products[name].append((timestamp, val[name].get("status")))
pprint.pprint(all_products)
...
'Awaken Deskpad': [('20210903212016', 'Fulfilled!'),
('20210904162630', 'Fulfilled!')],
'Awaken Deskpads': [('20210214070452', 'Gathering final numbers.'),
('20210503013145',
'Order placed. In queue for production.'),
('20210518024825', 'In production.'),
('20210601214541', 'In production.'),
('20210610195008', 'In production.'),
('20210612045914', 'In production.'),
('20210625082347',
'Production complete. In transit to NovelKeys.'),
('20210625225809',
'Production complete. In transit to NovelKeys.'),
('20210806073857',
'Production complete. In transit to NovelKeys.'),
('20210815050926',
'Production complete. In transit to NovelKeys.')],
...
After looking through the set of names, I manually created a map of "uncleaned" names to the preferred canonical name. This dictionary looks like:
name_cleanup = {
"Superuser Deskpads": "Superuser Deskpad",
"Sa Tatooine™": "SA Tatooine",
"Recall Deskpad GB": "Recall Deskpad",
"RAMA M6-C Oblivion Edition GB": "RAMA M6-C Oblivion Edition",
"Parcel Deskpads": "Parcel Deskpad",
"Oblivion V3.1 Deskpad GB": "Oblivion V3.1 Deskpad",
...
}
I also used the following snippet to identify groups of similar names:
import difflib
def print_similar_names():
for idx, name in enumerate(all_cleaned_products):
print(
difflib.get_close_matches(
name, [x for i, x in enumerate(all_cleaned_products) if i != idx]
)
)
[]
['GMK Midnight Rainbow', 'Mictlan Deskpads']
['GMK Honor', 'GMK Zooted']
['Bento Deskpad', 'Bento R2 Deskpads', 'Metropolis Deskpads']
['JTK Classic FC', 'GMK Classic Retro Zhuyin', 'JTK Classic FC R2']
...
Then used the following code to replace the old names in the data:
cleaned_data = {}
for timestamp, val in data.items():
if timestamp not in cleaned_data:
cleaned_data[timestamp] = {}
for name in val.keys():
# use the preferred "cleaned" name if possible
# otherwise keep the old name
new_name = name_cleanup.get(name, name)
cleaned_data[timestamp][new_name] = val[name]
all_cleaned_products = set()
for timestamp, val in cleaned_data.items():
for name in val.keys():
all_cleaned_products.add(name)
print("Names to be cleaned: ", len(name_cleanup))
print("Names before cleaning: ", len(all_products))
print("Names after cleaning: ", len(all_cleaned_products))
Names to be cleaned: 32
Names before cleaning: 194
Names after cleaning: 162
Just what we expected: there were previously 194 names, we consolidated 32 of them, for a total of 162 unique canonical product names.
Flattening the Data
Currently, the data is in a hierarchical structure, but we want to convert it into flat rows. In other words, convert from this:
"20220617092727": {
"BOX 75 Keyboard": {
"category": "keyboards",
"estimate": "Q3 2022",
"estimate_text": "Estimated Arrival: Q3 2022",
"status": "In production."},
}
to this:
{
"timestamp": "20220617092727",
"product_name": "BOX 75 Keyboard",
"category": "keyboards",
"estimate": "Q3 2022",
"estimate_text": "Estimated Arrival: Q3 2022",
"status": "In production."
}
Then, I created a Pandas dataframe with:
df = pd.DataFrame(data=flattened_data)
Plotting the Data
This dataframe was used with the data visualization library matplotlib
to analyze the data in several ways. The source code for all of this is available
here,
but most of the code is fairly basic filtering and aggregation with pandas.
Number of Product Updates
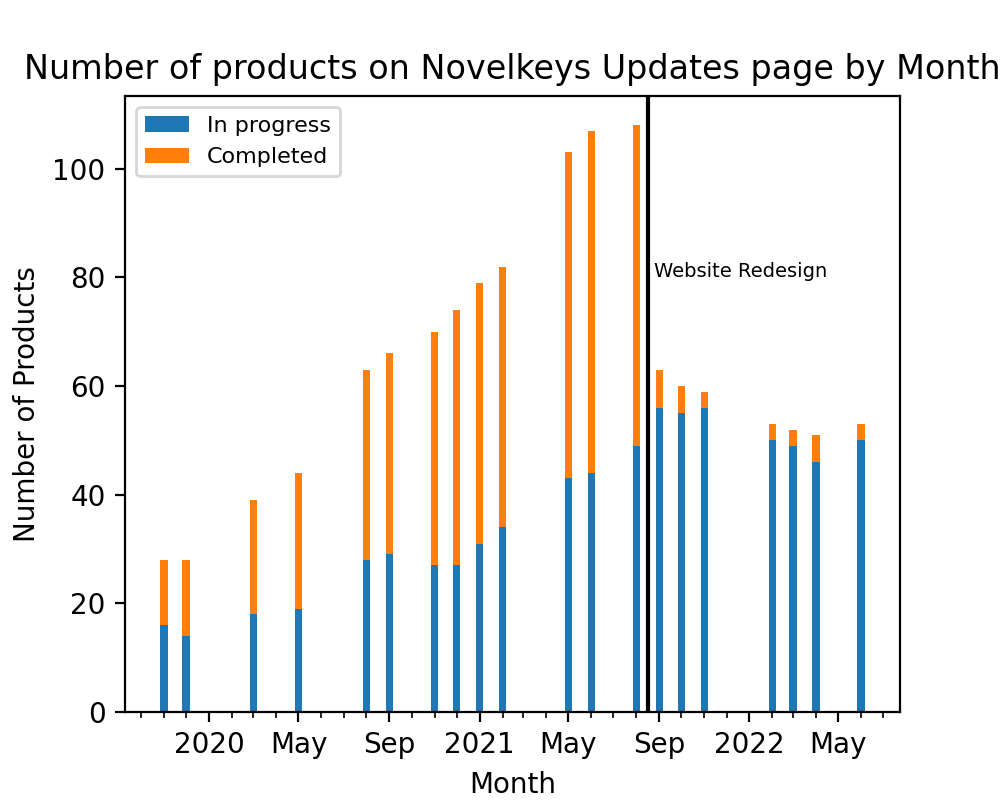
This trend shows steady growth from ~15 products in progress in late 2019 to peaking at ~60 products in Sept. 2021, then falling slightly from that level.
Timeline of Products
Looking at the date that a product is first and last seen on the website can give us some insight into the length of delivery for a product from its first appearance. These won't match up 100%, because the website is only scraped roughly once per month, but also contains some gaps longer than a month. This frequency should still be close enough for ballpark purposes.
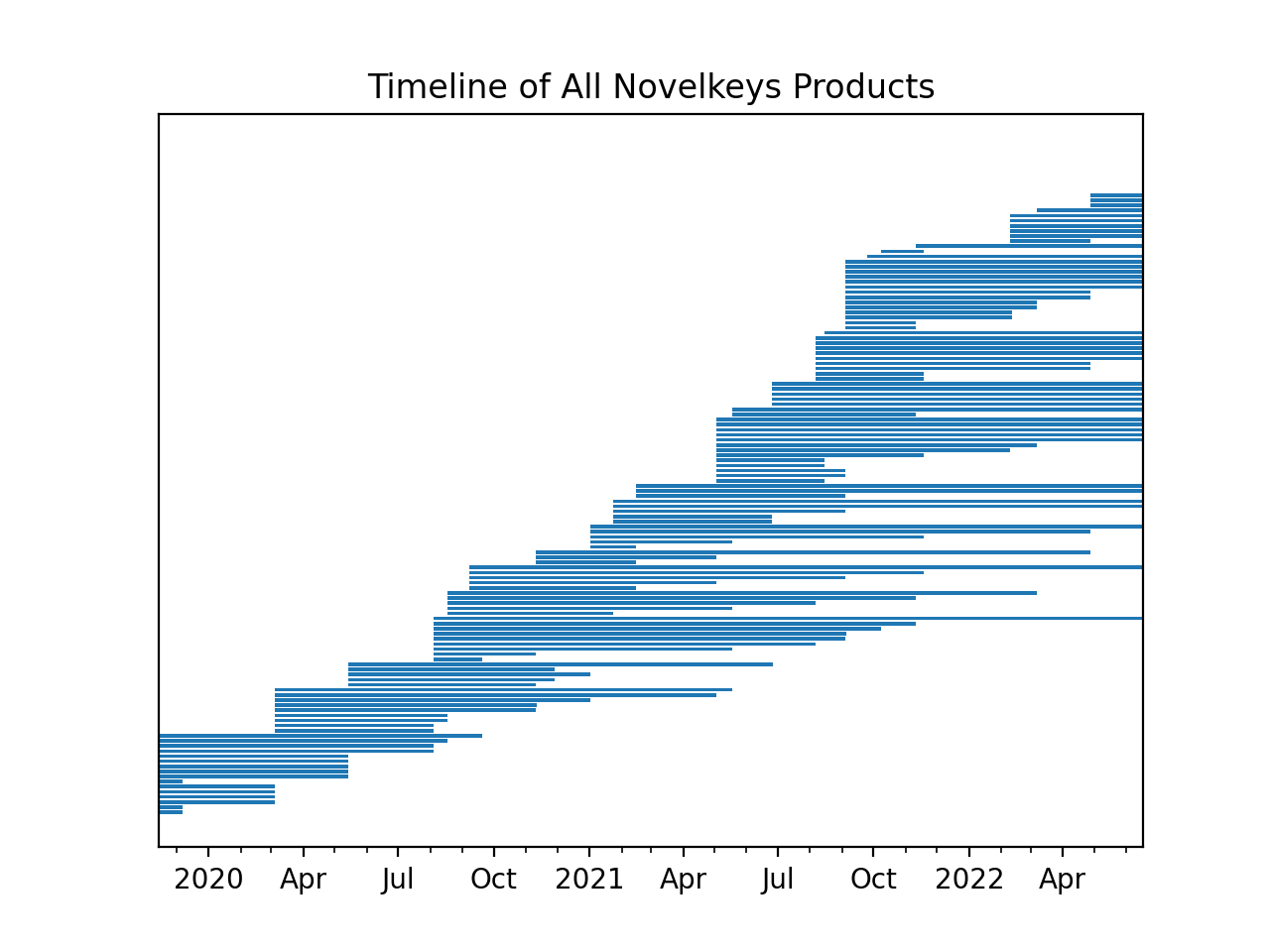
This plot shows every unique product, and when it was added/removed from the updates page. Not all products were officially stated as "completed", but I'm assuming that products no longer on the updates page have been completed.
This graph is a little hard to read, so let's break down the data more.
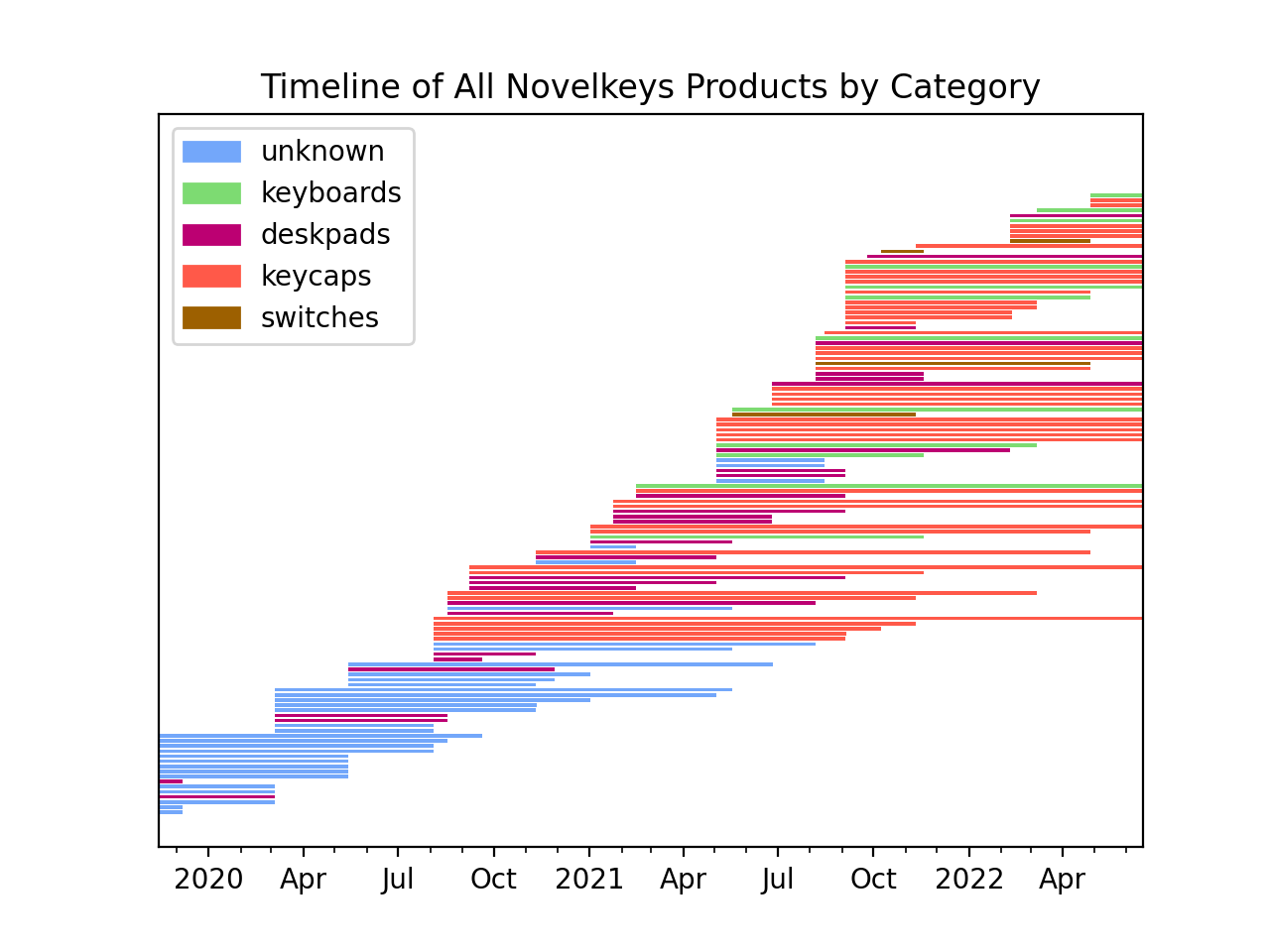
This plot color codes the products by category:
- keycaps - the plastic caps for a mechanical keyboard
- keyboards - the entire keyboard, including the caps
- deskpads - a cloth or synthetic mat to place under the keyboard/mouse
- switches - the part of the keyboard that registers a key press, and also controls the "feel" of the keyboard
The new website design (novelkeys.com) shows these categories explicitly, but the old design did not. I was able to deduce "deskpads" from the product name: e.g. "Colorchrome Deskpad". But the rest of the products fell into the "unknown" category. From manual inspection, most of these are keycaps, but even the product images don't show a difference. The keycaps are also shown on a keyboard, not standalone.
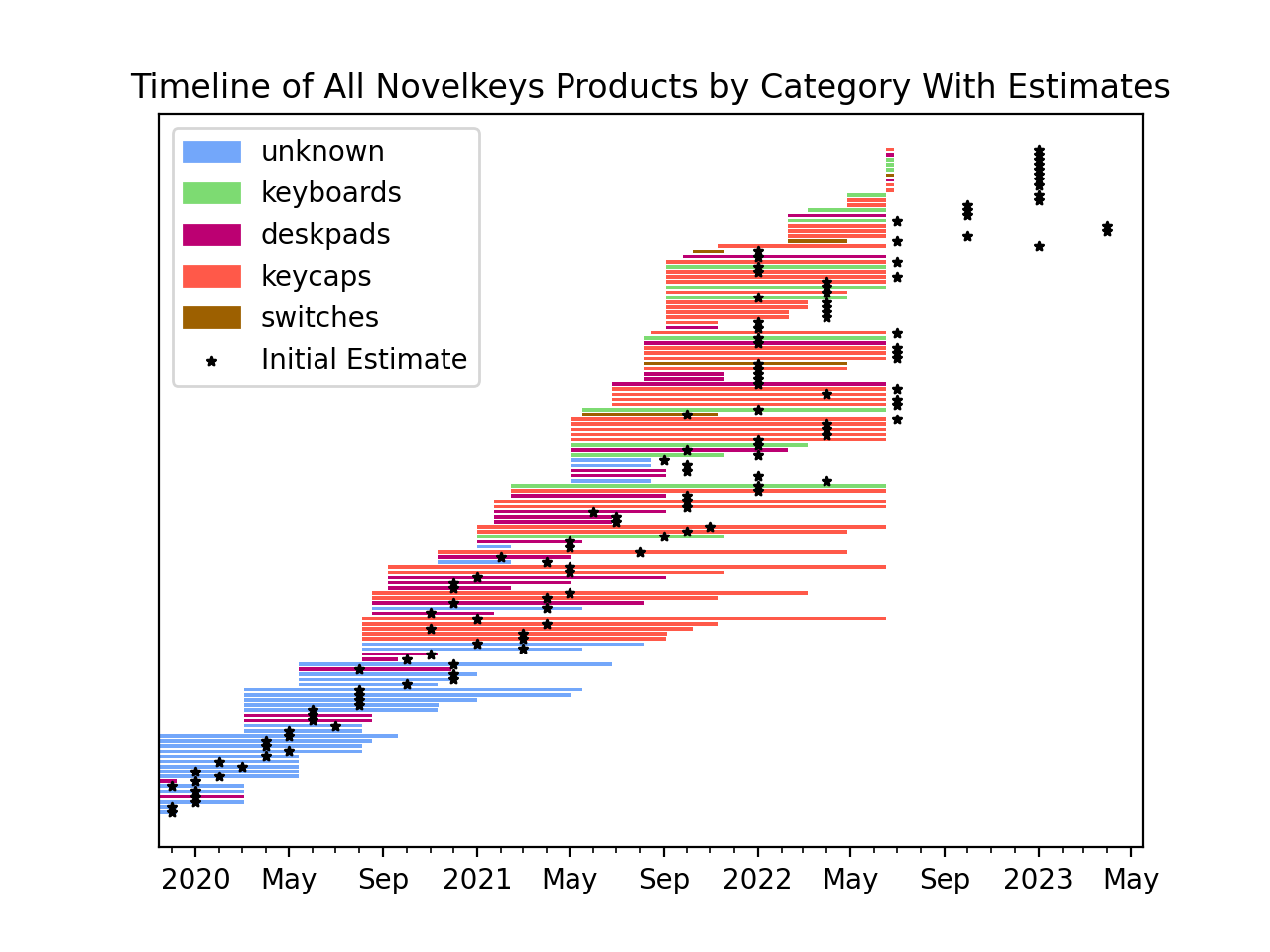
We can also take a look at the initial estimates of each product. In this plot, the "worst case" estimate is shown for each product. This is found by looking at either the monthly or quarterly estimate and using the last day in that period. For example, an estimated delivery of "August" translates to August 31. A "Q3" estimate translates to September 30.
As we can see in the graph, the provided estimates are usually optimistic. Because I only have data going back to November 2019, it's not clear whether this is a recent phenomenon caused by COVID-19 supply chain issues, or if these estimates are generally shorter than reality.
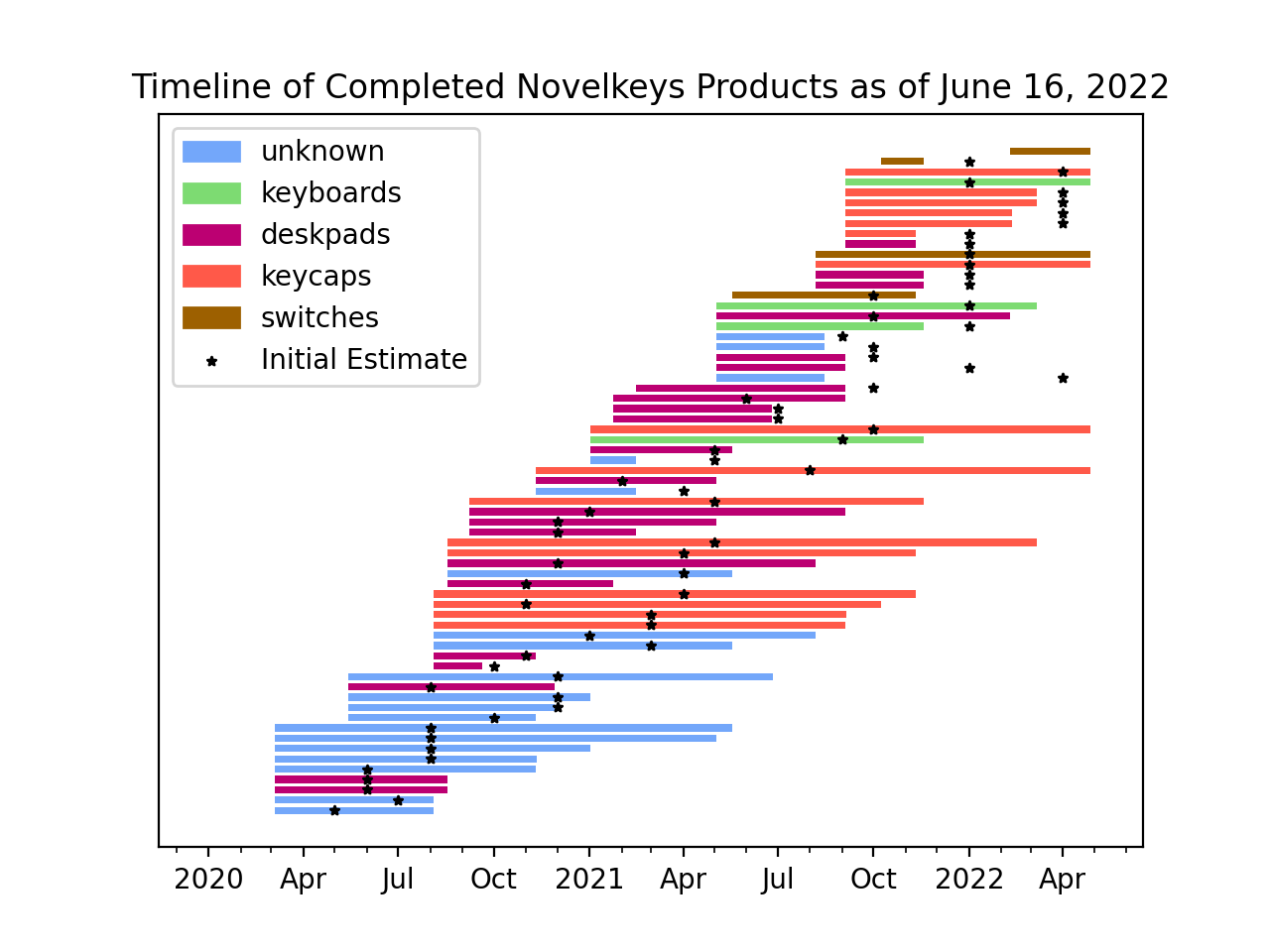
We can also filter this data more, to include only products that we have seen from start to finish. This means products that we didn't see added until after the first snapshot, and we saw completed before our last snapshot. This will help us get a more accurate understanding of delivery times by omitting incomplete product runs in the data.
This plot shows only products that we had a full picture of.
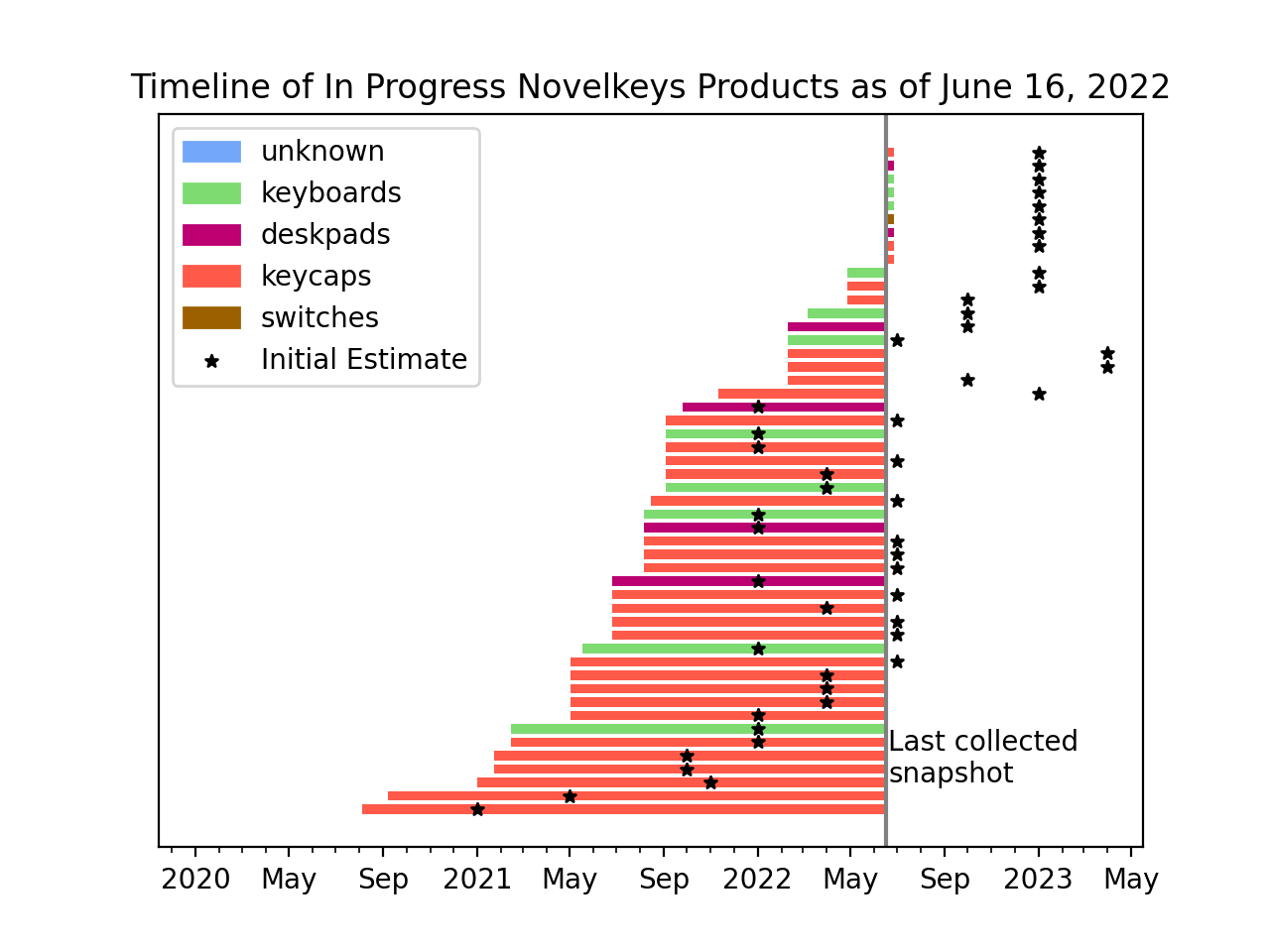
We can also do the opposite, and only look at products which are still in progress (as of June 2022).
This includes the longest-running product, "KAM Ghost" (shown at the bottom), which first appeared in August of 2020, with a December 2020 estimate. They now have an estimated delivery of Q3 2022.
Delivery vs. Estimated Delivery Time
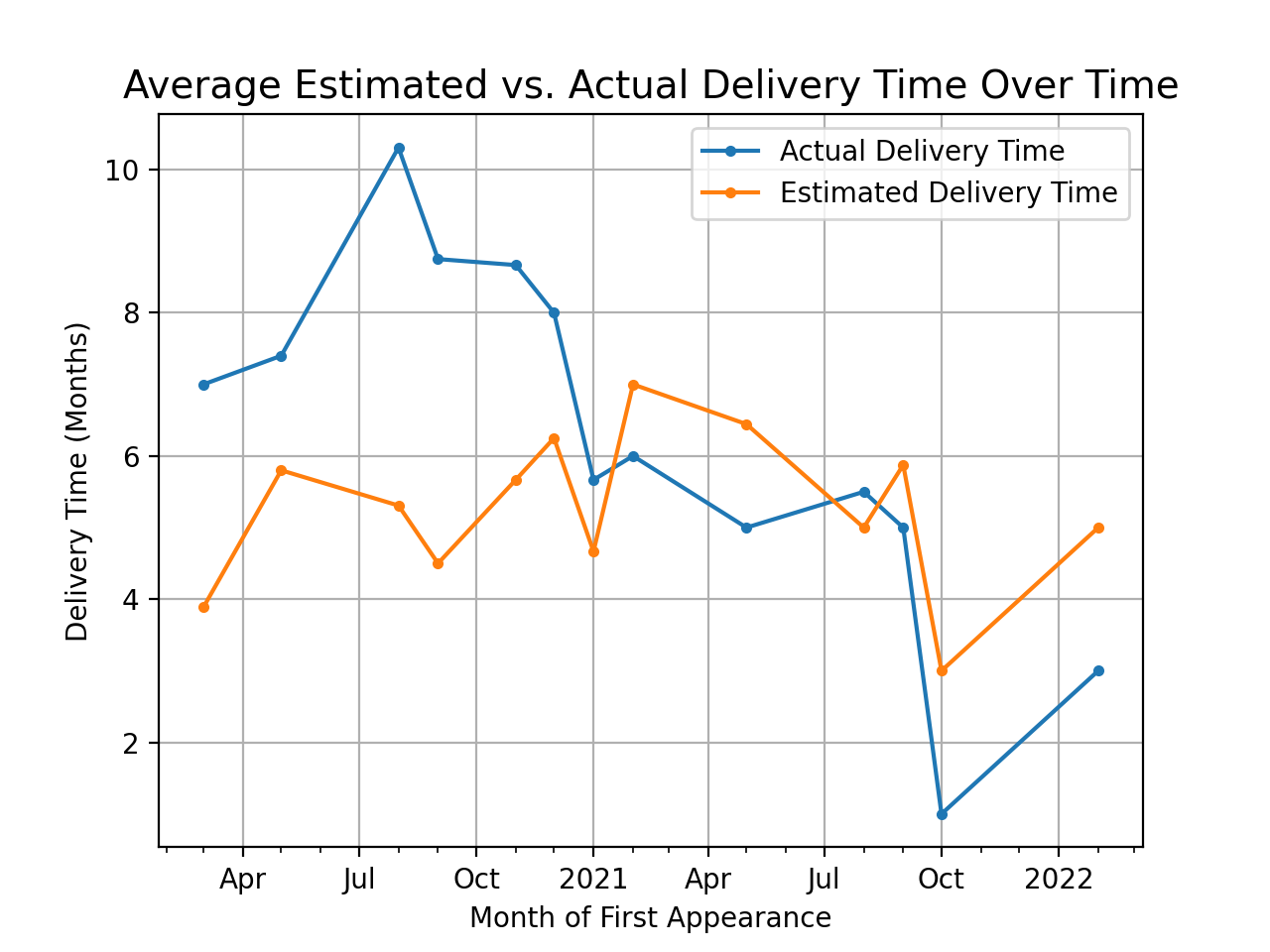
We can also compare the average delivery time for completed products based on their date of first appearance. This plot groups all completed products first seen in the same month, and averages together their completion date. It does the same with the average estimated (worst case) delivery time.
Interestingly, this shows a trend of a decreasing average delivery time, but I think this is just selection bias. Because we're filtering out the in progress products here, we're losing all the data points from recent in progress products and biasing the data towards products that completed early.
I think the only way to correct for this is to wait for all the currently in-progress products to complete, and re-run this plot with all the data.
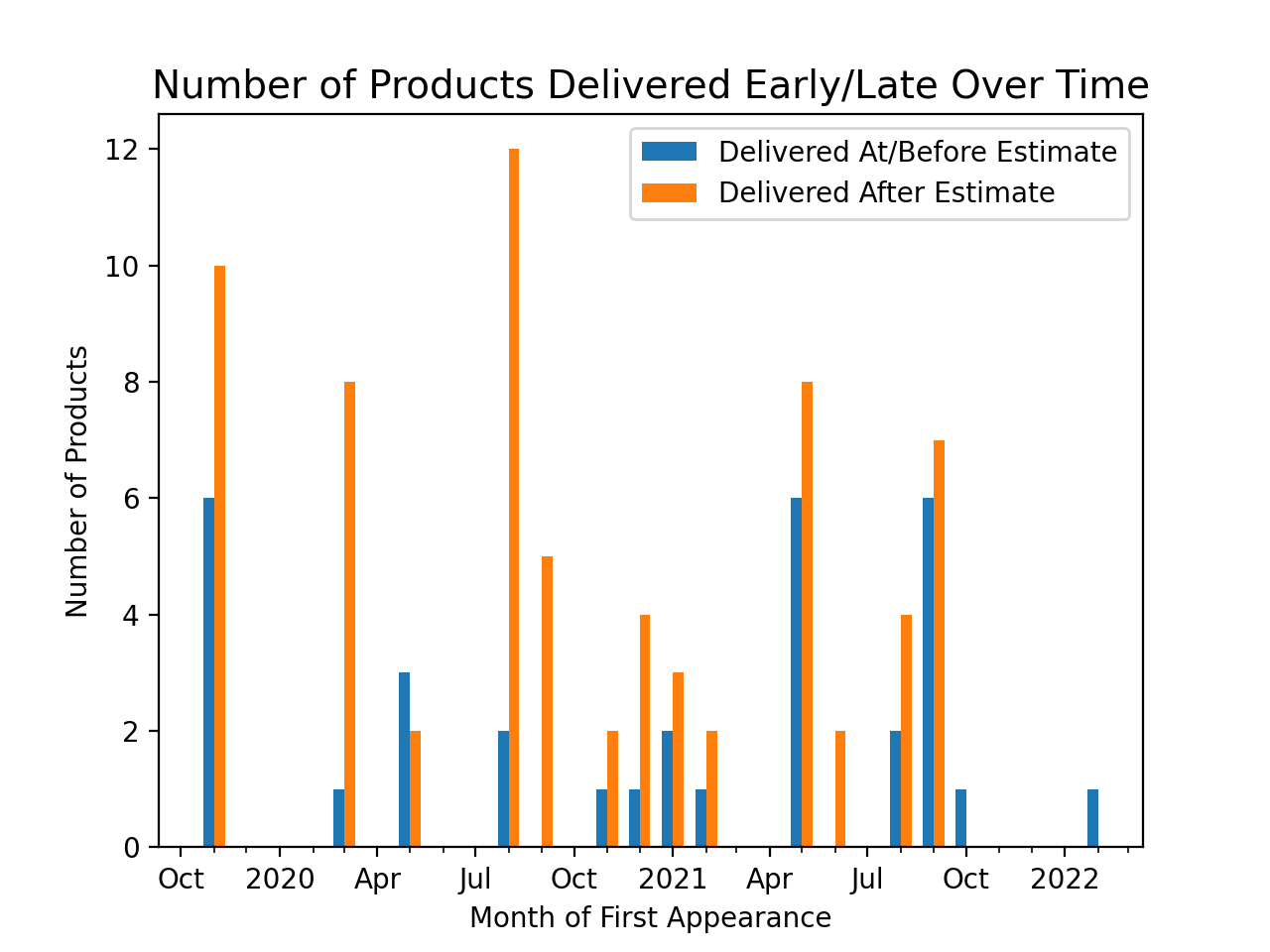
Trying to examine whether or not the previous trend was selection bias, I plotted for each month, the number of products released in that month that completed delivery before or after the initial estimate. This corrects for the previous selection bias, because I can still tell whether in-progress products have gone over the initial estimate, without knowing when exactly they will be delivered.
This plot also shows that these estimates are generally optimistic, with most of the products being delivered past the initial estimate.
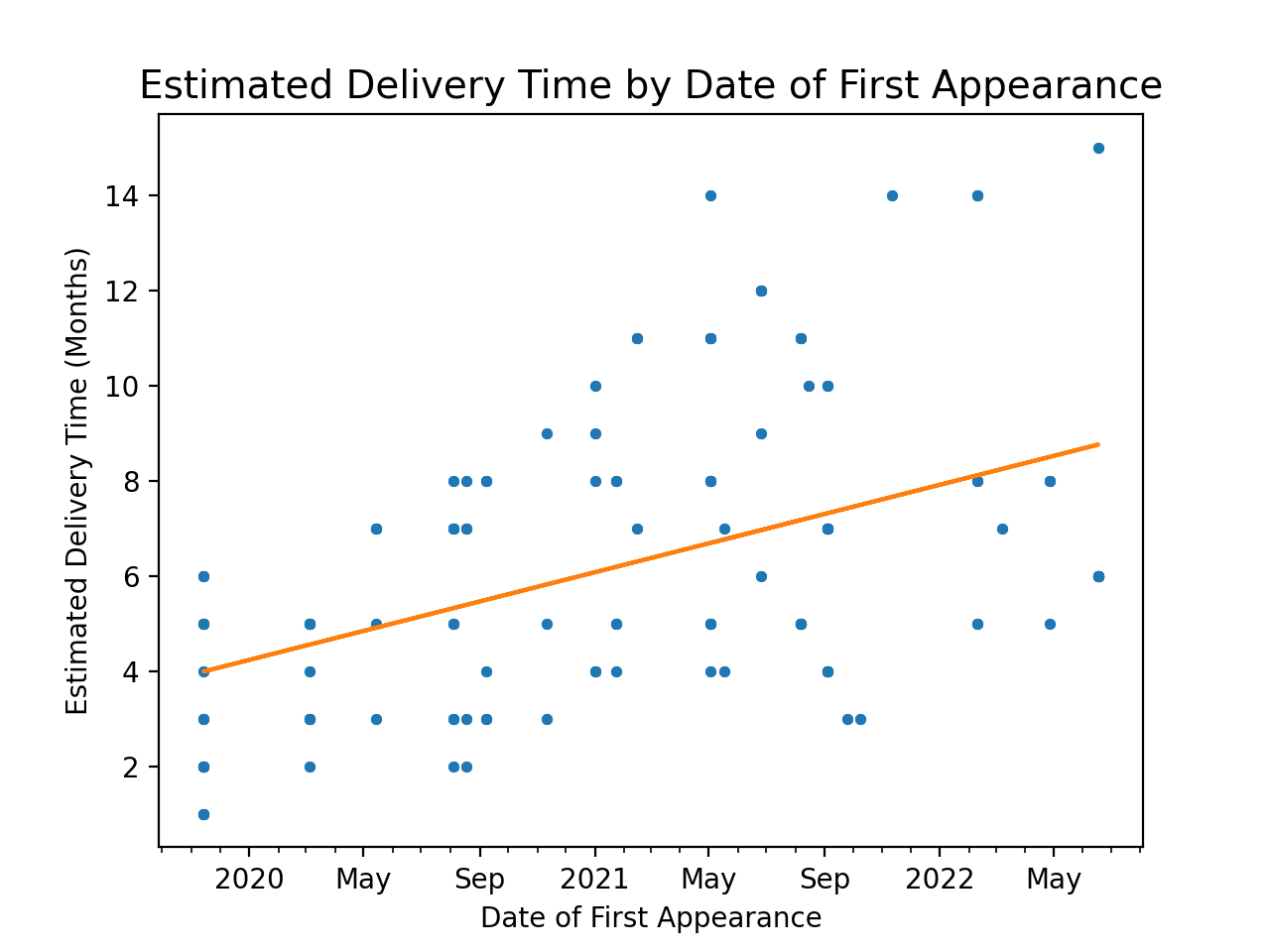
I was also curious if the increased delivery time affected the estimates, so I plotted each estimated delivery time over time and plotted the line of best fit.
This plot shows that the estimated delivery time is increasing, to more closely reflect reality.
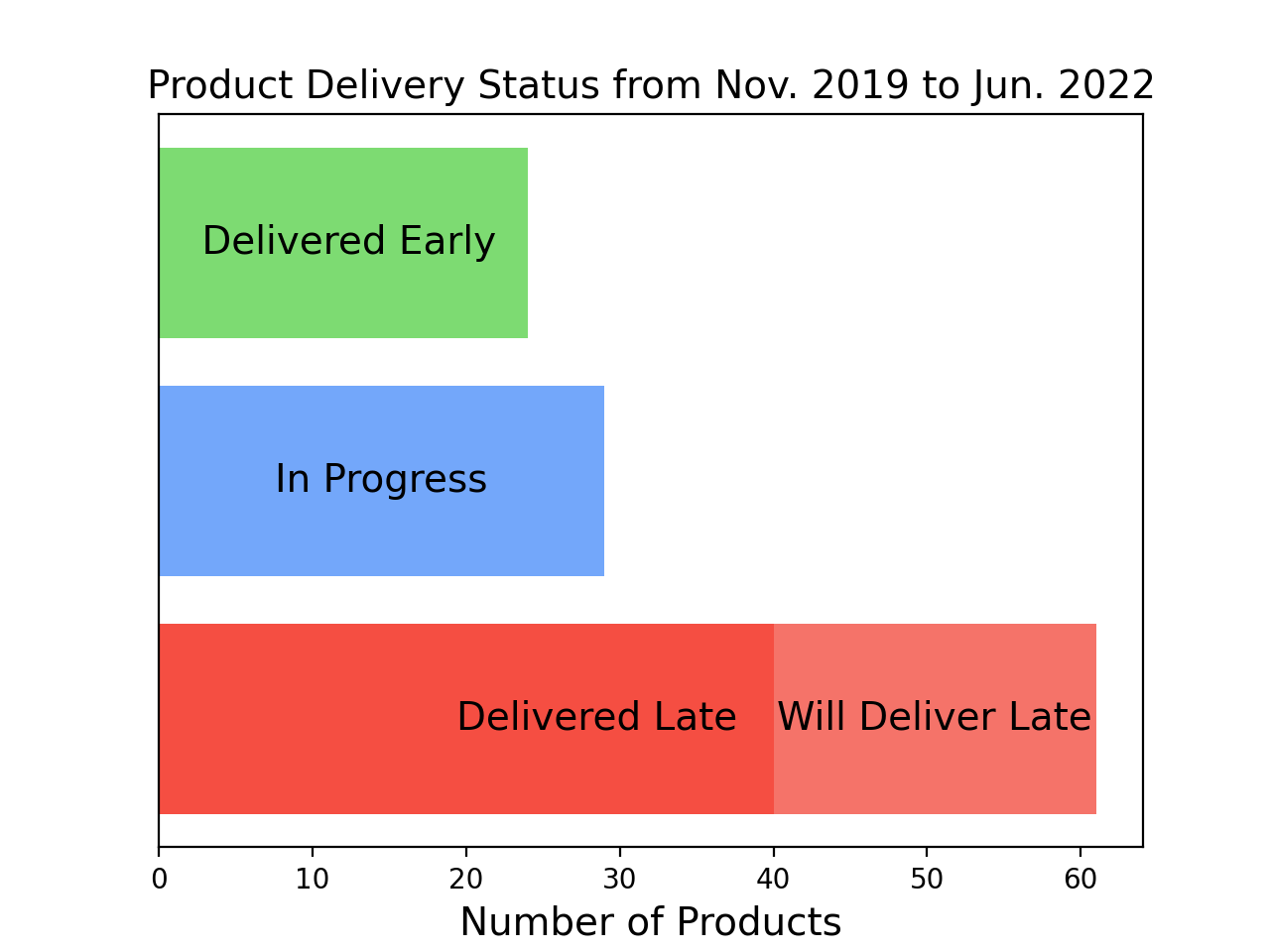
I also wanted to see the cumulative trends of delivery estimates. This plot shows four categories:
- Delivered Early: these products were delivered before the initial estimated date
- In Progress: these products are currently in progress and haven't yet exceeded the initial estimate
- Delivered Late: these products were delivered later than the initial estimate
- Will Delivery Late: these products are in progress, but already passed the initial estimated delivery date
Conclusion
The current status of my GMK Dots is "In Production", so I'm optimistic they will arrive by Q3 2022. Overall, it's apparent that the provided delivery estimates are a bit optimistic, but to their credit, I was only able to analyze products being manufactured through unprecedented supply chain disruptions, which especially affected China. Given what I know now, I would probably still order this product.
I hope this data was informative to any prospective buyers, or others waiting on their orders alongside me.
Source Code
All the code for this project is open source, and is available here: